-
코드 돌려보기 - Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation (Talking Head Generation)논문 후기와 구현 2024. 8. 3. 08:12728x90
Talking Head Generation
미국 대선이 다가오고 있다. 트럼프가 될지 해리스가 될지보다도 사실 내가 궁금한 것은, 이번 대선에서 Diffusion 기술이 어떤 위력을 발휘할 것인가이다. 24년 6월 15일 GitHub에 공개된 Hallo도 Diffusion을 활용한 Talking Head Generation 기술을 다룬다.
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
Flamingo라고, 투고되자마자 ChatGPT가 공개되어 어마어마한 결과물에 비해 주목을 많이 받지는 못한 불운의 논문이 있었는데, 하여튼 저때부터 뭔가 저런 억지 backronym으로 논문 이름을 짓는 게 아주 유행을 하는 것 같다. 개인적으로 막 좋아하지는 않지만, 나라도 논문을 저렇게 명명할 것 같다. 기억하기도 쉽고.
여하간, Hallo의 아키텍처는 아래와 같다:
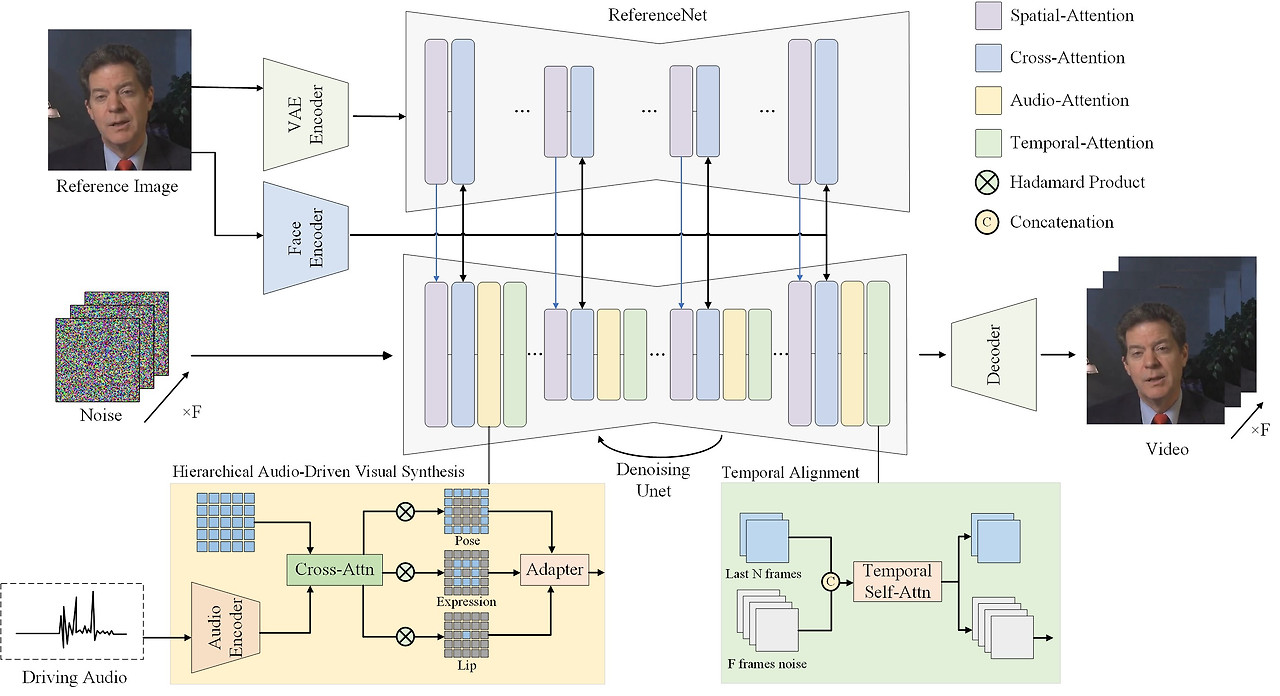
Hallo의 아키텍처 / 이미지 출처:https://github.com/fudan-generative-vision/hallo Hallo는 Driving Audio와 Reference Image(인물사진)만 넣으면, Driving Audio에 부합하는 동영상을 만들어준다.
코드 구동해보기
해당 GitHub에서는 Ubuntu 20.04 or 22.04, Cuda 12.1, A100의 환경을 제시한다. 하지만 나는 Nvidia GeForce RTX 4090 Laptop GPU, 32GB RAM을 갖춘 Windows 11 노트북에서 구동하였다. 솔직히 이것도 싼 건 아니다. 480만원 정도 되는 노트북이던데 부트캠프하는 동안 대여받은 거임ㅎㅎㅎ.
아무튼 CUDA 가상환경만 잘 구축한다면 Windows에서도 잘 돌아간다. 근데 대신
scripts/inference.py에 다음을 추가해줘야 한다.import sys sys.path.append(os.path.abspath('.'))또한 FFmpeg gyan빌드를 다운받아 bin 경로를 환경변수에 추가한다. 예를 들어 다음과 같다:

이것만 하고 나면, GitHub에서 하라는 대로 순서대로 하면 된다. (torch, CUDA 등 기본 환경은 설정되어있다는 가정)
conda create -n hallo python=3.10 conda activate hallo pip install -r requirements.txt pip install . git lfs install git clone https://huggingface.co/fudan-generative-ai/hallo pretrained_models그리고 알맞은 경로에 원하는 사진(jpg)와 오디오(wav)를 추가한 후, 다음을 실행한다.
python scripts/inference.py --source_image examples/reference_images/<YOUR IMAGE>.jpg --driving_audio examples/driving_audios/<YOUR AUDIO>.wav이때 다음을 주의한다:

10초 이내의 오디오로 동영상을 만드는 데 15분 이내가 소요된다. 이것저것 흥미롭게 만들어놔서 올리고는 싶은데, AI윤리 상 내가 아닌 다른 친구들에 대한 영상을 올리기도 그렇고, 내 영상을 올리자니 그것도 좀 부끄럽고 그래서...
한국어가 잘 안 되는 이유
이렇게 해서 코드를 돌려보면 알겠지만, 한국어는 굉장히 어색하다.

이미지 출처:https://github.com/fudan-generative-vision/hallo 그 이유는, 이 논문에서 쓰인 Audio Encoder가 wav2vec 1.0이기 때문. wav2vec은 WSJ 등 영어 오디오 데이터를 기반으로 학습되었기에 한국어는 아무래도 좀 어색할 수 밖에 없다.
_
loewen.tistory.com
'논문 후기와 구현' 카테고리의 다른 글
Multi-Conditioned Denoising Diffusion Probabilistic Model (mDDPM) for Medical Image Synthesis 논문 리뷰 (1) 2024.10.08 Spline-based Transformers 요약 (1) 2024.10.07 Coqui TTS (XTTS-v2) 한국어 Fine-Tuning (7) 2024.09.03 고등학생도 하는 GPT Fine-Tuning (AI-Hub 방언 데이터셋 활용해서 fine-tuning해보기) (9) 2024.09.02 KCC 2024 참여 후기 (0) 2024.08.03