-
FFN Fusion: Rethinking Sequential Computation in Large Language Models 리뷰: 바퀴의 발명은 끝나지 않았다.논문 후기와 구현 2025. 3. 31. 11:51728x90

오랜만에 쓰는 블로그 글..
0. AI 경량화
일단 DeepSeek 파동 전부터, LLM 경량화는 AI계의 꽤 오랜 화두였다. 국내에서는 SqueezeBits 등의 스타트업이 AI 양자화로 유명하고, distillation, pruning, MoE 등의 기법도 착실히 연구되고 있다.
이 논문은 NVIDIA에서 낸 논문인데, FFN Fusion이라는 새로운 경량화 기법을 제안한다.
1. 기존 경량화 기법의 문제점
- quantization: precision-accuracy trade-offs가 있다고 한다. Confusion metirc trade-off를 말하는 건 아닐 것 같고... 논문의 이 표현이 정확히 뭘 뜻하는지는 잘 모르겠지만, tensor의 float표현 precision이 낮아지면, 모델의 accuracy가 낮아진다는 뜻 아닐까, 생각해본다.
- pruning: 역시나 model accuracy를 해치지 않으면서 유의미한 중복(redundancy)을 가지치기는 힘들다. 즉, pruning은 고전적 ML같이 모델이 구조적일 때에 성능이 더 좋다는 것.
1.1. MoE는? DeepSeek는 성공했잖아.
1.1.1. 작은 블록의 문제점
- MoE는 추론 단계에서 고유한 문제를 가지고 있다. MoE의 근본적인 문제는 역설적으로 서브 모듈의 크기가 작다는 점에 기인한다. 왜냐하면 모듈 크기가 작아질수록 오히려 GPU 활용도가 낮아지기 때문이다. (wave quantization)
- MoE의 expert 모듈은 일반적인 일반 MLP보다 작아서, 위 문제들에 더 민감하게 영향을 받음
- 또한, MoE의 라우팅 메커니즘 자체도 작은 모듈로 구성되어 있어 동일한 문제 있음
그러므로 MoE는 빠르게 확장 한계에 도달한다.
1.1.2. 배치(batch) 크기의 영향
- MoE는 큰 배치에서는 잘 작동하는데, 작은 배치에서는 효율이 떨어진다.
- 문제는 더 많은 토큰이 모델을 통과할수록 더 많은 expert가 활성화되고 이로 인해 latency가 증가한다는 것.
- 일반 모델은 동일한 배치 크기에서 이미 최적의 성능을 내는 반면, MoE는 여전히 비효율적인 영역에서 작동 중이라는 것
- 결론적으로, MoE는 매우 큰 배치 크기일 때에만 그 장점을 제대로 발휘할 수 있으며, 일반적으로 더 자주 사용되는 중간 배치 크기에서는 토큰 수에 따른 성능 저하, 높은 저수준 오버헤드, 병렬화 스케일링 문제가 있음
2. FFN Fusion: "transformer 연산이 꼭 순차적이어야 함?"
우선 트랜스포머 구조를 다시 기억해보자.
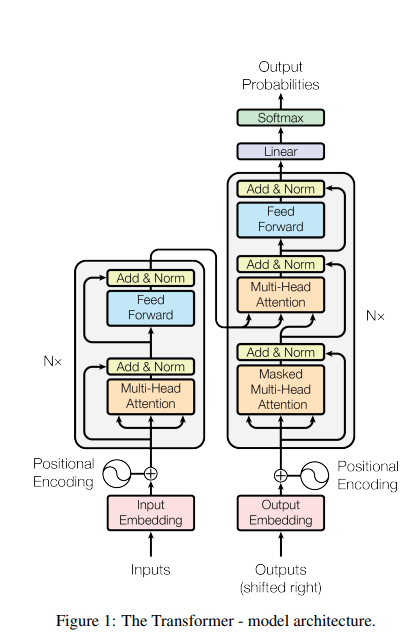
저기 보이는 Feed Forward가 이 논문에서 말하는 FFN이다. MLP와 같은 구조인데, Attention만 있는 Transformer는 비선형성을 줄 수 없으므로, FFN은 비선형성을 담당하는 역할을 한다.
LLM은 저 transformer 블록이 수십개 반복된 구조이다. 예를들어 LLaMA-7B에는 32개의 layer가 있다.
Transformer block 하나를 f(X)라고 할 때 이는 다음과 같이 표현할 수 있다:
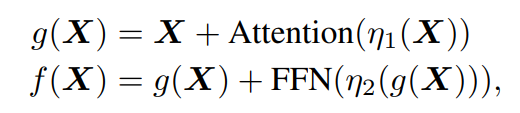
이 f(X)를 Puzzle이라는 LLM 최적화 프레임워크로 최적화를 진행한다. 그러면 많은 attention layer가 제거된다. 이를 다음과 같이 표현한다.

그러면 i번째 블록부터 i+c번째 블록까지의 일련의 과정을 다음과 같이 나타낼 수 있다.

이 FFN들의 합은 아래의 정리에 의해, 하나의 FFN으로 나타낼 수 있다.
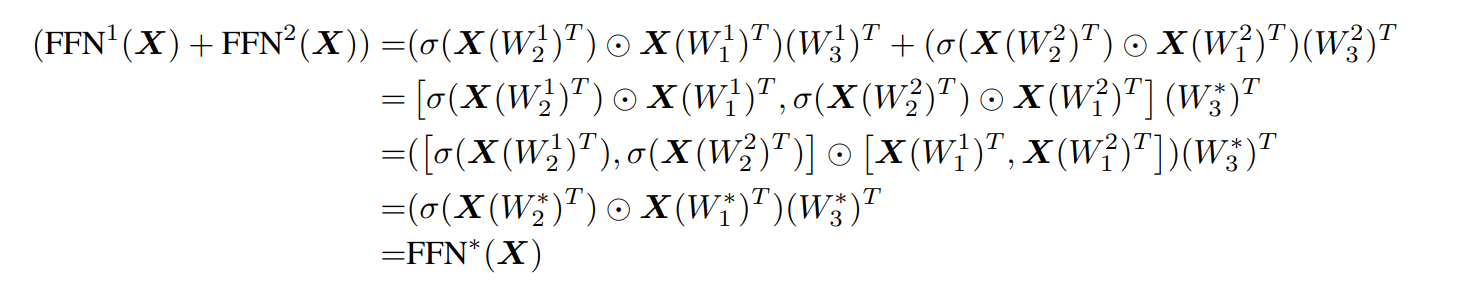

3. 텐서 병렬화, 과연 효율적일까?
텐서 병렬화는 여러 GPU에 분산하는 것을 말하는데, GPU 수에 비례해서 연산시간이 줄어들지는 않는다. 그 이유는 꽤나 아이러니한데, 연산량이 많을수록 GPU 성능이 더 좋아지기 때문이다. 그러므로 GPU의 처리량을 늘리고 블록 수를 줄이는 전략이 텐서 병렬화 환경에서 지연시간을 줄이는 데에 효과적이다. 그러므로 연속적인 FFN을 병합할 수 있다.
3.1. 이를 위해, 블록 간 쌍 실험을 시작한다.
어떤 블록 f(X)의 기여도를 h(X)로 나타내자.

그러고 블록 i를 제거했을 때 블록 j의 기여도를 다음과 같이 나타내자.

그러면 다음과 같이 metric을 만들 수 있다.

i-j 거리가 작다는 것은, 병렬화에 유리한, 즉 상호간 독립적이라는 것으로, FFN Fusion의 맛있는 먹잇감이다.

4. Attention 제거 레이어는 그렇다 치고... Attention 포함 레이어도 병렬화됨?
결론: 힘듦.
추후에 더 연구해봐야겠으나 우선 실험적으로는 유의미한 향상은 없었다고 한다.
우선 다음과 같이 M_max와 M_sum을 정의한다:

왜 연속된 4개의 블록에 대해서만 하는지, 왜 하필 4개인지는, 그냥 경험 상 그렇다고 한다.

여튼 (b) 그래서프에서 저렇게 metirc 값이 낮게 나오는 곳부터 greedy하게 병렬화하였지만, 성능 향상 폭이 그렇게 크지는 않았다고 한다.
5. 결론
2025년, 현재 AI의 흐름은 단연 Agent이다.
LLM을 새로 만들거나, fine-tuning해서 지지고 볶기 보다는, 이미 잘 만들어진 LLM의 Agent Architecture를 얼마나 잘 구축하는지가 새로운 기업 경쟁력이 되고 있다. (fine-tuning이 가성비가 그렇게 좋지 않다는 평가도 나오고 있고..)
바퀴는 누가 이미 잘 발명해놨으니, 이를 이용해 누가 수레를 더 잘 만드는지의 시대라고 해도 된다.
이는 사실.. 그동안 sLM 구축을 위한 여러 경량화 기법이 그닥 성공적이지만은 않았던 탓도 있으리라.
그러나 아직 바퀴의 발명이 끝나지 않았다. 끝난듯싶다가도 잊을만하면 DeepSeek가 나오고, 잊을만하면 이렇게 새로운 경량화 기법이 나온다.
'논문 후기와 구현' 카테고리의 다른 글