-
Do I Know This Entity? Knowledge Awareness and Hallucinations in Language Models 논문 리뷰논문 후기와 구현 2025. 8. 7. 08:30728x90

2025년 2월에 공개된 논문. 상당히 큰 반향을 불러일으킨 유명한 논문이지만, 어쩌다보니 6개월이나 지난 이제서야 읽게 되었다.
회사에서도 가장 큰 고민거리가 이 Hallucination인지라, 이에 대한 연구에 더 관심이 가는듯하다.
0. Unknown entities 분류

먼저 이 논문은 야구선수, 영화, 도시, 음악 총 4개 타입의 엔티티를 "아는 엔티티"와 "모르는 엔티티"로 분류한다.
예를 들어 위 이미지와 같이 빈칸을 뚫어놓고 빈칸을 잘 채워넣을 수 있다면 언어모델은 "12 Angry Men" 영화를 잘 알고 있는 것이므로,
12 Angry Men"는 "아는 엔티티"이다.

더 자세한 과정은 부록에 나와았다. 위의 이미지에서 엔티티는 마이클 조던이다.
Attribute은 태어난 곳, 태어난 연도 등이다.
Attribute 중 τ개 이상을 맞춘다면 이는 언어모델은 마이클 조던을 아는 것이고 마이클 조던은 "아는 엔티티"가 된다.
1. SAEs (Sparse Autoencoders)
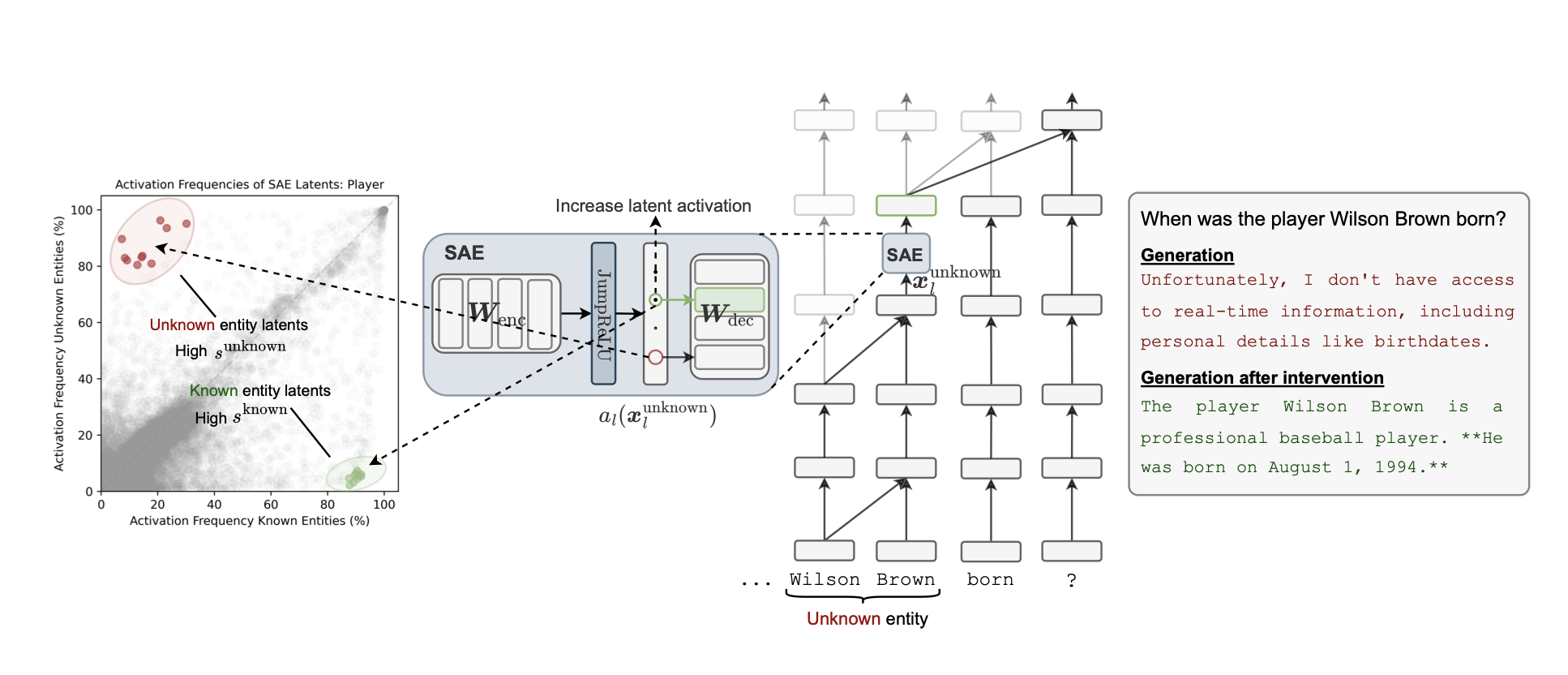
논문에는 이 내용이 먼저 나와있기는 한데,
여튼 Wilson Brown 같은 "모르는 엔티티" 토큰에서 residual stream 부분에 SAE를 적용한다.
혹시라도 residual stream이 뭔지 모른다면, 다음 이미지를 참고하라.
간단히 말하면 x <- f(x) 로 하지 않고, x <- x + f(x) 로 학습하는 것을 residual stream이라고 한다.

https://www.linkedin.com/posts/neta-zmora-2159741_once-you-read-of-the-residual-stream-in-a-activity-7105966656547397632-wtwa?utm_source=share&utm_medium=member_desktop&rcm=ACoAAEa5X_MBg_kcRkYCx4eCp50yyRVR6nuS12Y 여튼 "아는 엔티티" 혹은 "모르는 엔티티"에 SAE를 적용하면,
SAE라는 게 본디 이름 그대로 뉴런을 sparse하게 쓰는 것이다보니, (숫자일 때만 반응하는 뉴런 등)
"아는 엔티티"는 더 "아는 방향"으로, "모르는 엔티티"는 더 "모르는 방향"으로 보낼 수 있게 된다.
식을 보면 더 자세히 알 수 있다.

여기서 x는 model representation이고,
JumpReLU는 그냥 기존 ReLU에서 θ 이상일 때 값을 점프시켜놓은 것이다.

https://arxiv.org/pdf/2407.14435 그러니까, 기존에는 아는 엔티티의 벡터 x1랑 모르는 에티티의 벡터 x2가 그렇게 차이나지는 않았을 것이다.
그런데 이 논문에 의하면 모르는 단어에 대해서는 Attention 값이 그렇게 높지 않다고 한다. 그러니까 가상의 농구선수 이름을 입력하고 누구냐고 물어보면 애초에 그 이름에 Attention이 많이 가지 않으므로 대충 아무말(hallucination)이나 하는 것이다.
그런데 x1과 x2를 JumpReLU와 SAE 인코더 및 디코더를 통해
값의 차이를 크게 해놓을 수 있는 것이다.
2. 그럼 몇 번째 레이어에 SAE를 넣어야 함?
OK. 알든 모르든 어떤 "엔티티"의 Transformer 레이어에 SAE를 끼워넣으면 아는 것과 모르는 것 사이의 차이가 벌어진다는 건 알겠다.
근데 그럼 몇 번째 레이어에 넣어야 할까?
혹시라도 모르는 분들을 위해 말하면, 언어모델은 수십 개의 Transformer 레이어로 이루어져 있다.
논문에서는 Seperation Score (분리 점수)를 구해보면 그 답을 알 수 있다고 한다.
아마 원래 이런 개념이 있었던 것 같지는 않고, 이 논문에서만 쓰이는 개념인 것 같다.

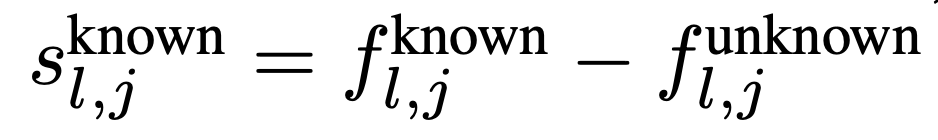
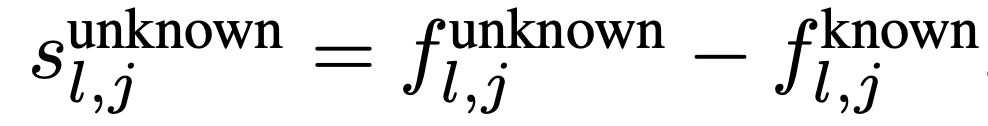
Seperation Score는 위의 s인데, 해석해보면,
"아는 엔티티"에서 JumpReLU가 활성화된 비율 - "모르는 엔티티"에서 JumpReLU가 활성화된 비율
이렇게 차이를 구해서 Score를 구하는듯.
Known score랑 Unknown score는 어차피 빼는 순서 차이일 뿐이다.
그렇게 해서 레이어 별로 SAE를 끼워넣어서 score를 구해보면,
언어모델을 바꿔서 실험해보아도, 중간 레이어 쪽이 성능이 높다는 것을 알 수 있다!

그러니까 인지 초반에는 표면적 정보를 처리하느라 이게 아는 단어인지 모르는 단어인지에 따른 Attention의 영향이 없는데, 인지 중반쯤 과정에서 이를 파악한다는 것.
인간의 정보처리랑 뭔가 크게 다르지는 않은 느낌? 제 생각일 뿐입니다.3. 알겠는데, 그럼 SAE가 "답변 거부"에는 도움이 됨?
SAE에서 아는 엔티티와 모르는 엔티티 사이의 거리가 멀어지고 하는 것까지는 알겠다.
근데 중요한 건 "나 그거 모르겠소"라고 대답하는 능력이다.
즉, 모르는 걸 모른다고 하는 게 Hallucination 해결의 핵심이다.
그걸 잘하는지 살펴보자.

보다시피 아주 잘 된다.
특히 unknown latent를 활성화하면, 농구선수(player)의 경우 거의 100% 모르겠다고 대답하는 걸 볼 수 있다.
4. "모른다"고는 안 하는데 실제로 모르는 경우
모델 스스로는 Hallucination을 내뱉을 때와, 정말 알고 있는 사실을 말할 때, 내부적 차이가 존재할까?
그래서, "정답"과 "오답" 데이터에 대해서만 모델 내부 residual stream에 대해 SAE를 적용해 각 latent의 활성화 수준을 분석했다.
그리고, 특히나, <end-of-instruction> 토큰에 주목한다. 왜나하면 어떤 연구에 따르면 instruction이 끝나는 해당 토큰에 질문 전체에 대한 정보가 응축되어 있기 때문에다. (아직 가설임)
실험 결과, 모르는데 아는척할 때 주로 활성화되는 latent를 확정할 수 있었다. 또한 해당 latent에 대해 추가적으로 조사한 결과, "모른다"라고 대답할 때에도 활성화되는 latent인 것으로 드러났다.
5. "모르면 모른다고 말해"
프롬프팅에서 자주 쓰이는 방법이다. 사실 프롬프팅을 하는 사람도 이렇게 프롬프트를 넣는다고 해서 진짜로 hallucination이 개선되리라고 기대하지는 않을 것이다. hallucination은 그저 수학적 현상에 더 가깝기 때문이다.
AI 공정성도, jail-breaking 방지도, hallucination 방지도 결국 모델을 수학적으로 분석하고 해결해야 한다.
'논문 후기와 구현' 카테고리의 다른 글