-
Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens 논문 리뷰논문 후기와 구현 2025. 8. 18. 18:51728x90

애리조나주립대의, 랩실 이름부터 근-본 있는 <데이터마이닝과 머신러닝 연구소>에서 2025년 8월 발행한 따끈따끈한 논문이다.
Few-shot Learning과 CoT는 현업에서 굉장히 많이 쓰이는 프롬프팅 기법이다.
현재 기준 두 논문 합치면 인용수가 7만이 넘음Fine-tuning의 한계점이 점점 명확해진 2024년 즈음부터는, 현업 언어모델의 많은 부분이 Few-shot Learning과 CoT에 크게 의존하고 있다.

CoT를 설명하는 논문: https://arxiv.org/pdf/2201.11903 그런데 이 논문은 가히 그 제목부터 충격적이다. CoT는 신기루일 뿐이었는가?
0. 일단 뭔가 수상함
CoT까지 갈 것도 없이, 일단 평소에 ChatGPT를 사용하다보면 모종의 수상함을 느낄 때가 많다. 앞이랑 뒤랑 다른 소리를 하는 것인데, 논문에서는 다음의 사례를 제시한다.
Q. 미국이 세워진 해는 윤년인가 평년인가?
A. 미국은 1776년에 세워졌습니다. 1776은 4로 나누어지는데, 100의 배수는 아닙니다. 즉 이는 윤년입니다. 그러므로 미국은 평년에 세워졌습니다.아니. 앞에서는 윤년이랬다가 뒤에서는 평년이랬다가...
사실 논문 저자들이 이 사례를 찾기 위해 꽤나 고생했을 것 같은 게, 저렇게 짧은 답변보다는 조금은 긴 답변에서 저런 현상이 훨씬 잘 일어난다.
LLM이 근본적인 논리구조를 파악하지 못한다는 연구는 정말 많은데, 특히, 추론 과정에서 무관한 절이 삽입되면 성능이 급격히 저하된다는 연구가 치명적인 것 같다.
1. 탐구 시작
이 논문에서는 task, length, format의 관점에서 CoT를 분석한다.
즉,
- task: CoT 추론이 전에 본 적 없는 task를 얼마나 잘 해내는가
- length: CoT 추론이 train-set의 chain 길이와 다른 길이로 일반화되는가
- format: CoT 추론이 질문 형태에 있어서 얼마나 민감한가
이를 위해 GPT-2 기반으로, 언어모델을 처음부터 다시 훈련해서 통제된 실험환경을 구축한다.
일반 언어모델을 지지고 볶은 게 아니라, 이렇게 처음부터 실험환경에 맞게 통제된 언어모델을 구축했다는 것부터가 이 논문을 멋있게 한다.
가설: CoT의 성공이 모델의 고유한 추론 능력 때문이 아니라, in-distribution 예시와 구조적으로 유사한 out-of-distribution(OOD) 테스트 사례에 대해 조건부로 일반화할 수 있는 능력에서 비롯된 것이다.
말이 좀 어려운데, 그러니까 CoT는 진짜 추론을 하는 게 아니라, 훈련 과정에서 학습한 추론 패턴과 비슷한 질문을 받게 되면 그것에 대해서만 대답할 수 있을 뿐이라는 것.
2. 어떤 문제를 낼 거냐면
아마도 일종의 암호를 풀게 하는 논리 추론 문제를 낸 것 같다.
1. APPLE → NCCYR 과 같은 변환이다. 이 예시는 알파벳을 13칸 미룬 것인데, 이를 ROT 변환이라고 한다. 밑의 표를 보면 이해가 쉽다.
A B C D E F G H I J N O P Q R S T U V W K L M N O P Q R S T X Y Z A B C D E F G U V W X Y Z H I J K L M 2. APPLE → EAPPL 과 같은 변환이다. 이를 Cyclic Position Shift라고 한다. 이 예시는 단어 시퀀스를 순환시킨 것이다.
어떤 랜덤 문자열에 대해서, ROT나 Cyclic Position Shift를 몇 번 반복한다.

위 수식에서 f_k 는 ROT나 Cyclic Position Shift 중 하나이다.
이렇게 하는 이유:
일반 자연어로 추론 능력을 시험하면, 데이터셋을 완전히 통제하기 힘들기 때문.
3. 테스트
아까 언급했듯이, 이 논문은 CoT의 효용을 아래 3가지 관점에서 평가한다.
- task: CoT 추론이 전에 본 적 없는 task를 얼마나 잘 해내는가
- length: CoT 추론이 train-set의 chain 길이와 다른 길이로 일반화되는가
- format: CoT 추론이 질문 형태에 있어서 얼마나 민감한가
그래서 각각에 대한 테스트 결과를 논문에 써놨는데, 결론이 비슷하므로 여기에서는 task에 대한 일반화 결과만 소개하겠다.
참고로 이 블로그에서는 논문에 자세하게 쓰여있는 수식 증명도 다 생략했는데, Appendix에 자세히 나와있으니 한번씩 봐보기를.
수식 증명을 엄청 자세히 써놓은 친절한 논문임.
여기서 논문에서는 TGC라는 개념을 도입한다.
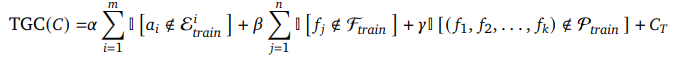
수식을 간단히 설명하자면,
- 새로운 element가 있는지: 예를 들어, 훈련 때에는 APPLE, BANANA만 봤는데 테스트에서 ZEBRA가 나오면 → TGC는 커짐
- 새로운 변환이 있는지: 훈련 때는 ROT만 봤는데, 테스트에서 Cyclic Position Shift가 나오면 → TGC는 커짐
- 새로운 변환 순서가 있는지: 훈련 때는 ROT → Cyclic Position Shift만 봤는데, 테스트에서 반대 순서가 나오면 → TGC는 커짐
- C_T는 Task의 고유 난이도 점수.
TGC를 이용해 테스트한 결과:

결과: TGC가 τ를 넘어가면, 모델이 정답을 맞출 확률은 지수적으로 떨어진다!
더 자세히 봐보면,

각각의 시나리오를 ID, CMP, POOD, OOD 라고 하는데,
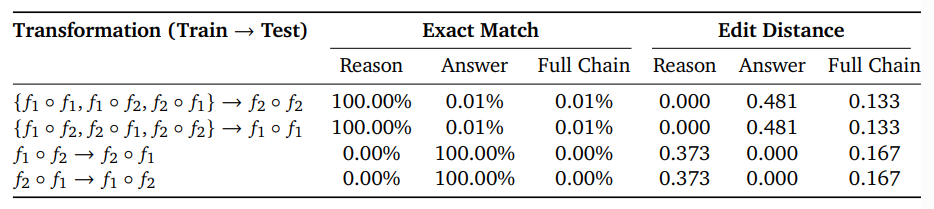
여기서 Full-Chain은 Reason과 Answer 모두 맞은 경우이다.
그런데, 위 표의 3, 4행 즉, POOD 시나리오의 경우 추론과정이 모두 틀렸음에도 정답률은 높았다는 것이 주목할만하다.
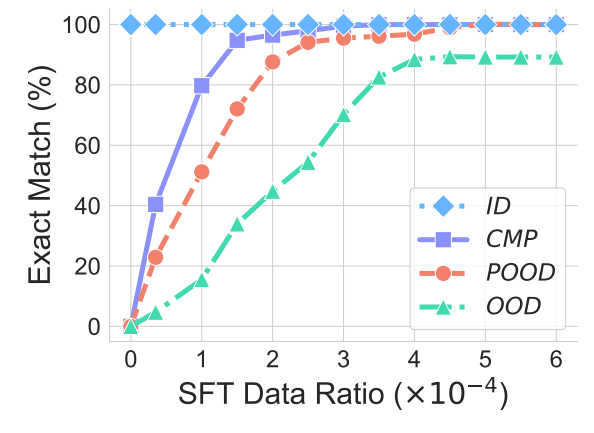
이번에는 불포 불일치를 줄이기 위해, Supervised Fine-Tuning(SFT)를 진행하였더니, 소량의 SFT만으로도 성능이 급격히 좋아지는 것을 확인할 수 있었다.
다른 테스트 결과는 생략하겠지만, 결론은 비슷하다.
테스트셋이 없는 추론 과정에 대해 LLM은 거의 실패했지만, 약간의 SFT만으로 성능을 올릴 수 있었다고.
4. 결론
1) 잘못된 자신감에 대한 경계
오랜 시간동안 CoT는 robust한 추론을 제공하는 모듈로 취급되었는데, 그러면 안 된다. LLM은 겉보기에는 그럴듯하지만 논리적으로 잘못된 CoT를 만들어낼 수 있다.
2) OOD 테스트 필요
테스트셋에 없는 추론에 대한 테스트를 진행해야 CoT의 robustness를 할 수 있다고,,, 한다.
근데 여기서 드는 의문은, 이 논문에서야 통제된 언어모델을 훈련시켰다 쳐도, 현대의 범용 언어모델의 진짜 어지간한 데이터는 이미 다 학습을 해버렸을 텐데, 그 언어모델이 테스트 과정에서 못 봤을 정도의 추론이 그렇게 유의미할까 싶기는 하다.
3) SFT도 만능은 아니다
이 논문에서는 LLM의 (unseen) CoT 논리력 결여를 SFT에 의존하여 해결한다. 그런데, SFT로는 "진정한 일반화"를 달성할 수 없다. SFT는 단지 "in-distribution 버블"을 약간 확장함에 불과함.
5. 이 논문에 대한 현업의 실익: "그래서, 딱히 문제될 게 있는가?"
학문적 호기심을 떠난 지극히 현업의 관점으로만 한번 봐보자.
여기서 현업은 AI 연구계 현업이 아니라, LLM Engineering을 해서 사내 언어모델을 만들어야 한다든가 하는 그런 현업들이다.
그럼 이 논문이 제공할 수 있는 인사이트는 제한적이다. 내 생각에는 기껏해야 "앞으로는 CoT 너무 믿지 말아야겠네" 정도.
왜냐하면 이미 범용 언어모델은 방대한 데이터셋을 통해 어지간한 추론과정을 이미 학습했기 때문이다.
그것이 설사 본질적인 논리 구조를 학습한 게 아니라고 한들, 현업의 입장에서는 CoT 프롬프팅을 했더니 대답을 잘한다면 CoT를 하지 않을 이유가 적어진다.
다만, Fine-tuning 만능주의가 2년 전 업계를 휩쓸었듯이 CoT 만능주의가 퍼지는 것은 막을 수 있겠다.
'논문 후기와 구현' 카테고리의 다른 글